
将大语言模型团队视为分布式系统
Language Model Teams as Distributed Systems
随着大语言模型能力的不断提升,由多个模型代理组成的团队受到广泛关注。单体模型在内存、上下文和能力方面存在基础性限制,因此将其组合成团队,以分担工作、进行通信并整合个人资源成为一种自然的应对方式。然而,关于团队何时有益、何时有害、需要多少代理以及如何设计结构以保持性能和效率等核心问题,目前仍缺乏基于原理的框架。如果不能妥善解决这些协调挑战,代理可能会互相覆写、产生冗余输出,并在推理过程中传播错误。
As large language models grow increasingly capable, teams composed of multiple model agents have attracted widespread attention. Single monolithic models remain fundamentally limited in memory, context, and ability, making it a natural response to compose them into teams to divide work, communicate, and pool individual resources. However, there is still a lack of a principled framework to address core questions such as when a team is helpful, when it hurts, how many agents to use, and how to design structures to maintain performance and efficiency. Without careful orchestration to address these coordination challenges, agents may overwrite one another, produce redundant outputs, and propagate errors through chains of reasoning.
研究人员提出,不应通过试错来设计和测试大语言模型团队,而应将分布式系统作为创建和评估这些团队的理论基础。从单体语言模型到多代理系统的演变,反映了计算技术本身从单处理器向结合多台机器的分布式架构发展的历史。大语言模型团队与分布式系统共享四个核心属性:第一是独立性,代理依赖本地上下文运行,对全局状态仅有部分可见性;第二是通信,代理通过传递消息进行协调;第三是并发性,多个代理同时执行任务;第四是易错性,代理可能会产生幻觉、停滞或输出错误。
Researchers propose that instead of designing and testing large language model teams through trial and error, distributed systems should be used as a principled foundation for creating and evaluating these teams. The evolution from single to multi-agent language model systems mirrors the historical development of computing itself, which transitioned from early single processors to distributed architectures combining many machines. Large language model teams share four core properties with distributed systems: independence, where agents operate on local context with partial observability of the global state; communication, where agents coordinate by exchanging messages; concurrency, where multiple agents execute tasks simultaneously; and fallibility, where agents may hallucinate, stall, or produce incorrect outputs.
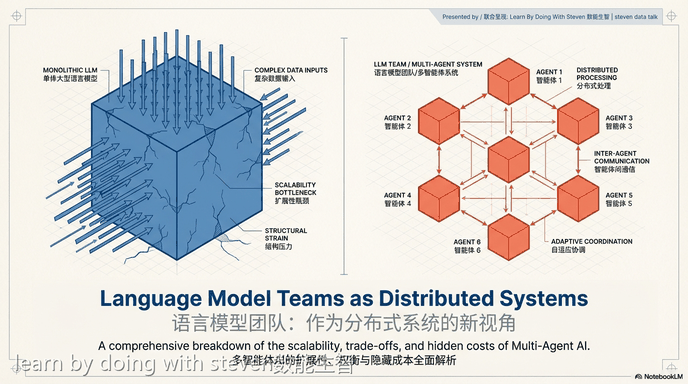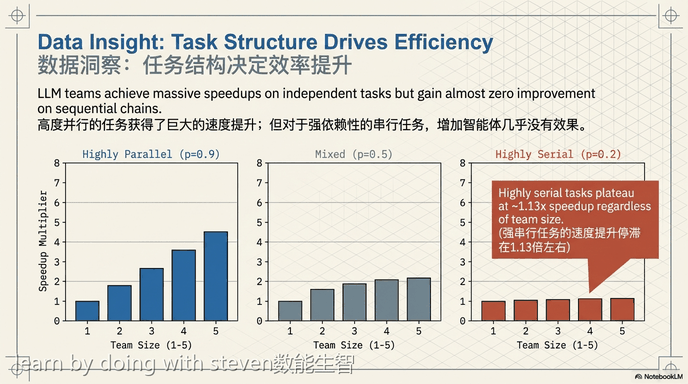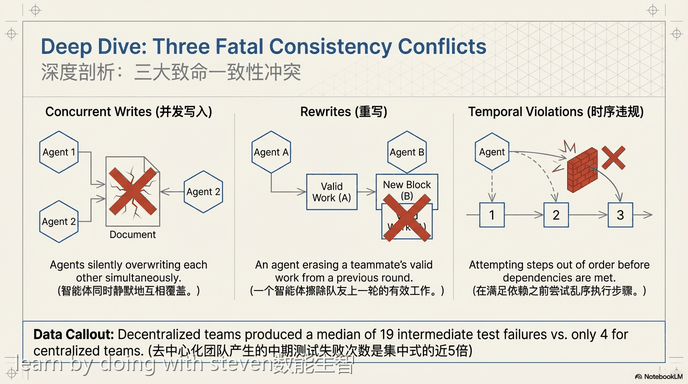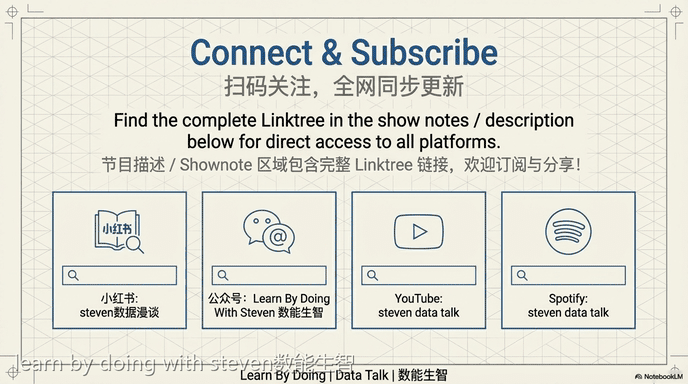
该研究通过让大语言模型团队在协作编程任务中进行测试,验证了这一理论框架。在可扩展性方面,大语言模型团队的效率提升遵循阿姆达尔定律。将工作分配给多个代理所能带来的性能提升,主要取决于基础任务的可并行化程度。具有独立子任务的高度并行化任务通过扩展团队规模获得了明显的效率提升,而包含混合依赖或高度串行依赖的任务在增加代理数量时,速度提升较小甚至没有改善。
The research validated this theoretical framework by testing large language model teams on collaborative coding tasks. Regarding scalability, the efficiency gains of large language model teams follow Amdahl’s Law. The extent to which distributing work across multiple agents improves performance depends primarily on the parallelizability of the underlying task. Highly parallel tasks with independent subtasks achieved significant efficiency gains by scaling team size, whereas tasks with mixed or highly serial dependencies showed little to no improvement when the number of agents increased.
团队架构的选择会带来效率、一致性和稳健性之间的权衡。与由中央协调者预先分配任务的团队相比,允许代理自主分配任务的去中心化自协调团队通常效率较低。去中心化架构增加了协调成本,导致更多的通信消息和代理处于空闲等待状态的轮次。同时,去中心化协调引发了更多的一致性冲突,例如多个代理同时写入并覆写同一文件,或在依赖项未完成前尝试执行后续任务,从而导致更高的中间测试失败率。
Architectural choices introduce tradeoffs between efficiency, consistency, and robustness. Compared to preassigned teams where a central coordinator allocates tasks, decentralized self-coordinating teams, which allow agents to claim tasks autonomously, generally exhibit lower efficiency. Decentralized architectures increase coordination overhead, resulting in more communication messages and idle rounds where agents wait. Meanwhile, decentralized coordination leads to more consistency conflicts, such as multiple agents concurrently writing to and overwriting the same file, or attempting to execute subsequent tasks before dependencies are finished, thereby causing higher rates of intermediate test failures.
尽管去中心化团队面临更严峻的协调难题,但它们在缓解落后者延迟方面表现更好。在固定任务分配的集中式团队中,如果一个代理处理速度过慢或出现波动,整个团队的下游进度都会停滞。去中心化团队允许较快的代理接管未完成的任务,从而动态重新分配工作,缩小了因单一代理缓慢而造成的时间差距。
Although decentralized teams face more severe coordination challenges, they perform better in mitigating straggler delays. In centralized teams with fixed task assignments, if one agent processes tasks too slowly or exhibits variability, the downstream progress of the entire team stalls. Decentralized teams allow faster agents to flexibly pick up unfinished tasks, dynamically reallocating work and reducing the time gap caused by a single slow agent.
部署大语言模型团队还需要考虑性能与成本效率的权衡。由于代理需要沟通、同步和管理一致性,将任务分配给多个代理会产生额外的计算成本和令牌消耗。研究结果表明,这种令牌消耗的增加往往超过了速度的提升,特别是在去中心化团队结构以及处理具备串行依赖关系的任务时,这一现象尤为明显。
Deploying large language model teams also requires considering the tradeoff between performance and cost-efficiency. Because agents must communicate, synchronize, and manage consistency, distributing work across multiple agents incurs additional computational costs and token usage. Research findings indicate that this increase in token consumption often outpaces the gains in speed, a phenomenon that is particularly pronounced in decentralized team structures and when processing tasks with serial dependencies.
总结而言,分布式计算为理解大语言模型团队行为、预测系统限制和诊断故障提供了严谨的分析框架。随着这些多代理系统的大规模部署,缺乏合理的协调机制不仅会导致性能下降,还会引发错误传播,并消耗大量的计算、能源和资金成本。将这些团队的设计建立在正式的分布式系统框架之上,有助于构建更高效、更可预测和更负责任的大语言模型应用。
In conclusion, distributed computing provides a rigorous analytical framework for understanding large language model team behavior, predicting system limits, and diagnosing failures. As these multi-agent systems are deployed at scale, poorly coordinated mechanisms will not only lead to underperformance but also propagate errors and consume substantial compute, energy, and financial costs. Grounding the design of these teams in a formal distributed systems framework helps build more efficient, predictable, and responsible large language model applications.
感谢您的阅读。如果您对相关内容感兴趣并希望探索更多,诚挚邀请大家关注 Learn By Doing With Steven 数能生智 以及 steven数据漫谈 播客。您可以在 YouTube、Spotify、小红书、微信公众号、YouTube Music 等各大社媒与音频平台找到我们,获取涵盖数据与人工智能领域的深度节目。所有社交媒体平台的链接均已包含在节目描述或 shownote 区域的 linktree 中。
Thank you for reading. If you are interested in related content and wish to explore further, we sincerely invite you to check out the Learn By Doing With Steven channel and the steven data talk podcast. You can find us on YouTube, Spotify, Xiaohongshu, WeChat Official Account, YouTube Music, and other major social media and audio platforms to access in-depth episodes covering data and artificial intelligence. All social media platform links are included in the linktree located in the program description or shownote area.
https://arxiv.org/pdf/2603.12229 https://linktr.ee/learnbydoingwithsteven
#大语言模型 #分布式系统 #人工智能 #多智能体 #学术研究 #LearnByDoingWithSteven #StevenDataTalk #LLM #AI #DistributedSystems #MultiAgent #TechPodcast
